本文是 SRE deep dive into Linux Page Cache 的阅读笔记
Page Cache#
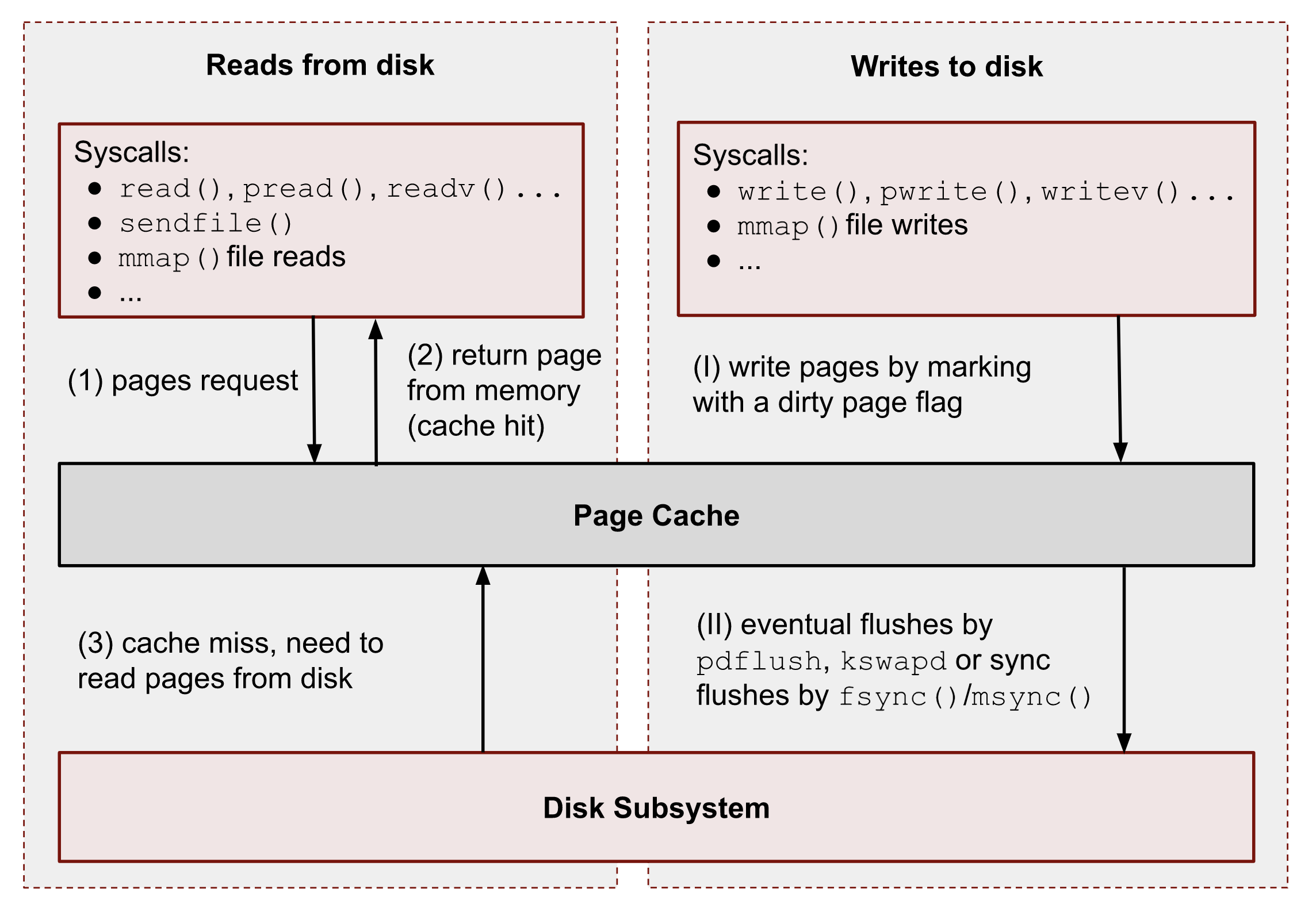
如图,在非 Direct IO 的情况下
读取:
- 用户态程序需要从磁盘读取数据时,会调用特定的系统调用,例如
read()、pread()、readv()、mmap()、sendfile()等 - Linux 内核首先检查请求的数据是否已经存在于 Page Cache 中:
- 如果数据已经在 Page Cache:内核直接返回结果,无需进行磁盘 IO
- 如果数据不在 Page Cache:内核必须从磁盘加载数据,并在返回结果之前,将数据存储到 Page Cache 中,以便后续访问可以直接命中
- 如果内存不足(无论是在整个系统还是调用进程所属的 cgroup 中),内核需要进行内存回收(memory reclaim),腾出足够的空间后再加载数据。从这一刻起,后续对该文件相同部分的读取请求(无论来自哪个进程或 cgroup)都会直接从 Page Cache 获取数据,而不会再触发磁盘 IO,直到被再次驱逐
写入:
用户态程序需要写入数据时,也会调用特定的系统调用,例如
write()、pwrite()、writev()、mmap()等与读取不同,内核先将数据写入 Page Cache,再异步地将数据写入磁盘。由于写入的异步特性,调用
write()的进程并不知道内核何时真正将数据刷新到磁盘,但它可以确保后续read()操作会读取到最新的数据。Page Cache 在进程和 cgroup 之间保持数据一致性。这些未刷入磁盘的数据页被称为脏页(dirty pages)Linux 提供了以下机制,强制将数据持久化到磁盘:
fsync(): 阻塞进程,直到目标文件的所有脏页及其元数据(metadata)被同步到磁盘fdatasync(): 与fsync()类似,但不会同步元数据msync(): 与fsync()类似,但用于mmap()映射的文件使用
O_SYNC或O_DSYNC打开文件,使所有文件写入默认同步,并分别相当于fsync()和fdatasync()系统调用
Read ahead#
首先创建文件,并且 drop cache
$ dd if=/dev/random of=/var/tmp/file1.db count=128 bs=1M
$ sync; echo 3 | sudo tee /proc/sys/vm/drop_caches
# 或者执行 vmtouch /var/tmp/file1.db -e 清除指定的文件的所有页
然后执行
with open("/var/tmp/file1.db", "br") as f:
print(f.read(2))
通过 strace 追踪系统调用可以看到
openat(AT_FDCWD, "/var/tmp/file1.db", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=134217728, ...}) = 0
ioctl(3, TCGETS2, 0x7fffe5da8e30) = -1 ENOTTY (Inappropriate ioctl for device)
lseek(3, 0, SEEK_CUR) = 0
clock_gettime(CLOCK_MONOTONIC, {tv_sec=499161, tv_nsec=921468379}) = 0
read(3, "y%I\346t\366q\251\36\276W\204\251\301\24!R\7\201\216^\274\367V\344\222<\30\303 \360\315"..., 4096) = 4096
虽然读取 2 字节,但是 Python 的 Buffer IO 会读取 4K 大小。并且由于内核的 read ahead 逻辑加载了 4 页,总共 16K 的数据
$ vmtouch /var/tmp/file1.db
Files: 1
Directories: 0
Resident Pages: 4/32768 16K/128M 0.0122%
Elapsed: 0.002299 seconds
P.S. 关于内存页大小为 4K 可以参考 https://draven.co/whys-the-design-linux-default-page/
如果我们想要控制 read ahead 逻辑,那么可以通过 fadvise
import os
with open("/var/tmp/file1.db", "br") as f:
fd = f.fileno()
os.posix_fadvise(fd, 0, os.fstat(fd).st_size, os.POSIX_FADV_RANDOM)
print(f.read(2))
这里使用 POSIX_FADV_RANDOM 告诉内核访问模式为随机,内核会抑制顺序预读
$ vmtouch /var/tmp/file1.db
Files: 1
Directories: 0
Resident Pages: 1/32768 4K/128M 0.00305%
Elapsed: 0.001997 seconds
参考 man 2 posix_fadvise。posix_fadvise 的参数可以为
POSIX_FADV_NORMAL指定应用程序对指定数据的访问行为没有特别的建议。如果对打开的文件未提供任何建议,则此选项为默认特性。POSIX_FADV_SEQUENTIAL指定应用程序预计会按顺序访问指定数据,从较低偏移量到较高偏移量。POSIX_FADV_RANDOM指定应用程序预计会以随机顺序访问指定数据。POSIX_FADV_WILLNEED指定应用程序预计在不久的将来会访问指定数据。POSIX_FADV_DONTNEED指定应用程序预计短期内不会访问指定数据。但不一定会导致 Page Cache 会完全被驱逐POSIX_FADV_NOREUSE指定的数据只会被访问一次。在 Linux 2.6.18 之前,
POSIX_FADV_NOREUSE的语义与POSIX_FADV_WILLNEED相同——这可能是一个错误。从 Linux 2.6.18 到 Linux 6.2,这个标志是无操作(no-op),即调用它没有任何效果。从 Linux 6.3 开始,POSIX_FADV_NOREUSE表示内核的页面替换算法可以忽略由该标志标记的已映射页缓存的访问。
我们再来看一下 mmap 的版本
import mmap
with open("/var/tmp/file1.db", "r") as f:
with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm:
print(mm[:2])
系统调用如下
openat(AT_FDCWD, "/var/tmp/file1.db", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=134217728, ...}) = 0
ioctl(3, TCGETS2, 0x7ffe218688c0) = -1 ENOTTY (Inappropriate ioctl for device)
lseek(3, 0, SEEK_CUR) = 0
fstat(3, {st_mode=S_IFREG|0644, st_size=134217728, ...}) = 0
fcntl(3, F_DUPFD_CLOEXEC, 0) = 4
mmap(NULL, 134217728, PROT_READ, MAP_SHARED, 3, 0) = 0x7ffbbc600000
$ vmtouch /var/tmp/file1.db
Files: 1
Directories: 0
Resident Pages: 1024/32768 4M/128M 3.12%
Elapsed: 0.001721 seconds
mmap() 建立映射本身不加载物理页;首次访问触发缺页并可能伴随有限的顺序预读,具体窗口由内核 read ahead 算法动态调整。若需要显式预取,可使用 MAP_POPULATE(在 mmap 时预触发缺页)或 madvise(..., MADV_WILLNEED);观测到较大驻留(例如数 MB)取决于实现与访问轨迹,非通用保证。MAP_LOCKED 可在映射时对页加锁(等价于针对映射区域的 mlock),受 RLIMIT_MEMLOCK 与权限约束
脏页(Dirty Page)#
第一组数据修改不满一页
with open("/var/tmp/file1.db", "br+") as f:
print(f.write(b"ab"))
$ vmtouch /var/tmp/file1.db
Files: 1
Directories: 0
Resident Pages: 1/32768 4K/128M 0.00305%
Elapsed: 0.002267 seconds
默认页面大小是 4K。在仅写入 2 字节后,我们缓存了 1 页。如果你的写入小于页面大小,你将在写入之前进行 4KB 的读取,以便填充页面缓存
我们再来看一下 mmap 的版本
import mmap
with open("/var/tmp/file1.db", "r+b") as f:
with mmap.mmap(f.fileno(), 0) as mm:
mm[:2] = b"ab"
$ vmtouch /var/tmp/file1.db
Files: 1
Directories: 0
Resident Pages: 1024/32768 4M/128M 3.12%
Elapsed: 0.002731 seconds
默认情况下, mmap() 即使是为了写请求,也产生了更多 Page
对于脏页来说
- 可以通过
/proc/meminfo获取全局的脏页信息
$ cat /proc/meminfo | grep Dirty
Dirty: 18900 kB
- 针对特定 cgroup 读取
memory.stat文件来获取更细粒度的脏页信息:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.stat| grep dirty
file_dirty 16384
如果进程使用了
mmap()进行文件写入,且没有关闭,我们可以从/proc/PID/smaps获取进程的详细内存统计信息。smaps文件按照虚拟内存区域(VMA) 细分统计,并包含以下两类脏页信息:Private_Dirty– 该进程生成的私有脏页Shared_Dirty– 和其他进程写入的脏页,共享的
$ cat /proc/227360/smaps | grep file1 -A 12 708dd8c00000-708de0c00000 rw-s 00000000 00:1a 2459918 /var/tmp/file1.db Size: 131072 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 4 kB Pss: 4 kB Pss_Dirty: 0 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 4 kB Private_Dirty: 0 kB Referenced: 4 kB Anonymous: 0 kB如果想针对某个文件获取脏页信息,Linux 提供了两个关键的 procfs 文件:
/proc/PID/pagemap/proc/kpageflags
mincore检查特定内存页是否驻留在物理内存中#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <sys/stat.h> #include <sys/mman.h> #include <unistd.h> #include <string.h> int main(int argc, char *argv[]) { if (argc < 2) { fprintf(stderr, "Usage: %s <file_path>\n", argv[0]); return EXIT_FAILURE; } const char *path = argv[1]; // 打开文件 (O_RDONLY 只读, O_NOFOLLOW 防止符号链接, O_NOATIME 避免更新时间) int fd = open(path, O_RDONLY | O_NOFOLLOW | O_NOATIME); if (fd == -1) { perror("open"); return EXIT_FAILURE; } // 获取文件大小 struct stat st; if (fstat(fd, &st) == -1) { perror("fstat"); close(fd); return EXIT_FAILURE; } size_t size = st.st_size; size_t page_size = sysconf(_SC_PAGESIZE); size_t pages = (size + page_size - 1) / page_size; // 向上取整页数 if (size == 0) { fprintf(stderr, "File is empty.\n"); close(fd); return EXIT_FAILURE; } // 使用 mmap 映射文件到内存 void *mm = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, 0); if (mm == MAP_FAILED) { perror("mmap"); close(fd); return EXIT_FAILURE; } // 分配 mincore 结果数组,每个页 1 字节 unsigned char *cached = calloc(pages, sizeof(unsigned char)); if (!cached) { perror("calloc"); munmap(mm, size); close(fd); return EXIT_FAILURE; } // 调用 mincore 进行查询 if (mincore(mm, size, cached) == -1) { perror("mincore"); free(cached); munmap(mm, size); close(fd); return EXIT_FAILURE; } // 计算驻留的页数 size_t resident_pages = 0; for (size_t i = 0; i < pages; i++) { if (cached[i] & 1) { // 低位为1表示驻留在内存中 resident_pages++; } } printf("Resident Pages: %zu/%zu %zu/%zu bytes\n", resident_pages, pages, resident_pages * page_size, size); free(cached); munmap(mm, size); close(fd); return EXIT_SUCCESS; }mlock()/mlock2()/mlockall()目的:将地址区间或整个进程地址空间对应的物理页标记为 unevictable,避免页被回收或换出,降低关键路径访问的抖动与尾延迟。
基本行为:
mlock(void *addr, size_t len):锁定区间内页(页对齐,部分覆盖按整页计算)。可能立即触发缺页,预先把页驻留到内存。mlock2(void *addr, size_t len, int flags):Linux ≥ 4.4。支持MLOCK_ONFAULT,按“首次缺页时再锁定”策略,避免一次性预触发大量缺页导致的尖峰。mlockall(int flags):MCL_CURRENT锁定当前所有映射;MCL_FUTURE将未来建立的映射也锁定;MCL_ONFAULT(Linux ≥ 4.4)按首次缺页再锁定,效果类似MLOCK_ONFAULT。
资源/权限限制:
- 非特权进程受
RLIMIT_MEMLOCK(ulimit -l)限制,超过将失败(通常ENOMEM)。具备CAP_IPC_LOCK的进程可突破该限制(或被放宽)。 - 被
mlock*的页会计入 cgroup 的使用,并在统计中体现为unevictable。这既可能是匿名页,也可能是文件页(Page Cache)。
- 非特权进程受
与 Page Cache 的关系:文件映射被
mlock*后,对应的缓存页同样变为不可回收,这在热点只读数据(例如索引页)上可显著稳定时延,但需谨慎使用以免挤压系统可回收内存。
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.stat | grep -E 'unevictable|anon|file'
anon 1645015040
file 684802048
file_mapped 67792896
file_dirty 90112
file_writeback 0
anon_thp 1455423488
file_thp 14680064
inactive_anon 0
active_anon 1645367296
inactive_file 645099520
active_file 68870144
unevictable 0
workingset_refault_anon 0
workingset_refault_file 2661
workingset_activate_anon 0
workingset_activate_file 92
workingset_restore_anon 0
workingset_restore_file 0
memory.swap.high和memory.swap.max(cgroup v2)基本概念:
memory.swap.current:当前 cgroup 的交换区(swap)使用量(字节)。memory.swap.max:cgroup 允许的最大 swap 使用量(硬上限)。写入max取消上限;写入0禁止使用 swap(即该 cgroup 的匿名页不可被换出)。memory.swap.high:swap 使用的“软上限/高水位”。超过后,内核对该 cgroup 施加抑制与回收压力,尽量把使用量压回阈值以下;不会像max一样直接拒绝,但会产生停滞(可从 PSI 侧面感知)。
与内存限额的关系:
memory.max/memory.high约束 RAM(匿名+文件页计费);memory.swap.*仅约束 swap 使用。- 将
memory.swap.max=0常与适度的memory.high联用,既避免匿名页被换出,又通过软高水位限制 RAM 膨胀导致的系统性压力。
- 将
为了控制脏页刷新频率,Linux 内核有几个 sysctl 参数。可以使后台写回 (writeback) 过程或多或少地激进:
$ sudo sysctl -a | grep dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 1500
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 1500
vm.dirtytime_expire_seconds = 43200
当 *_bytes 非 0 时,对应的 *_ratio 被忽略;*_centisecs 以 1/100 秒为单位控制脏页到期与回写周期。
mmap#
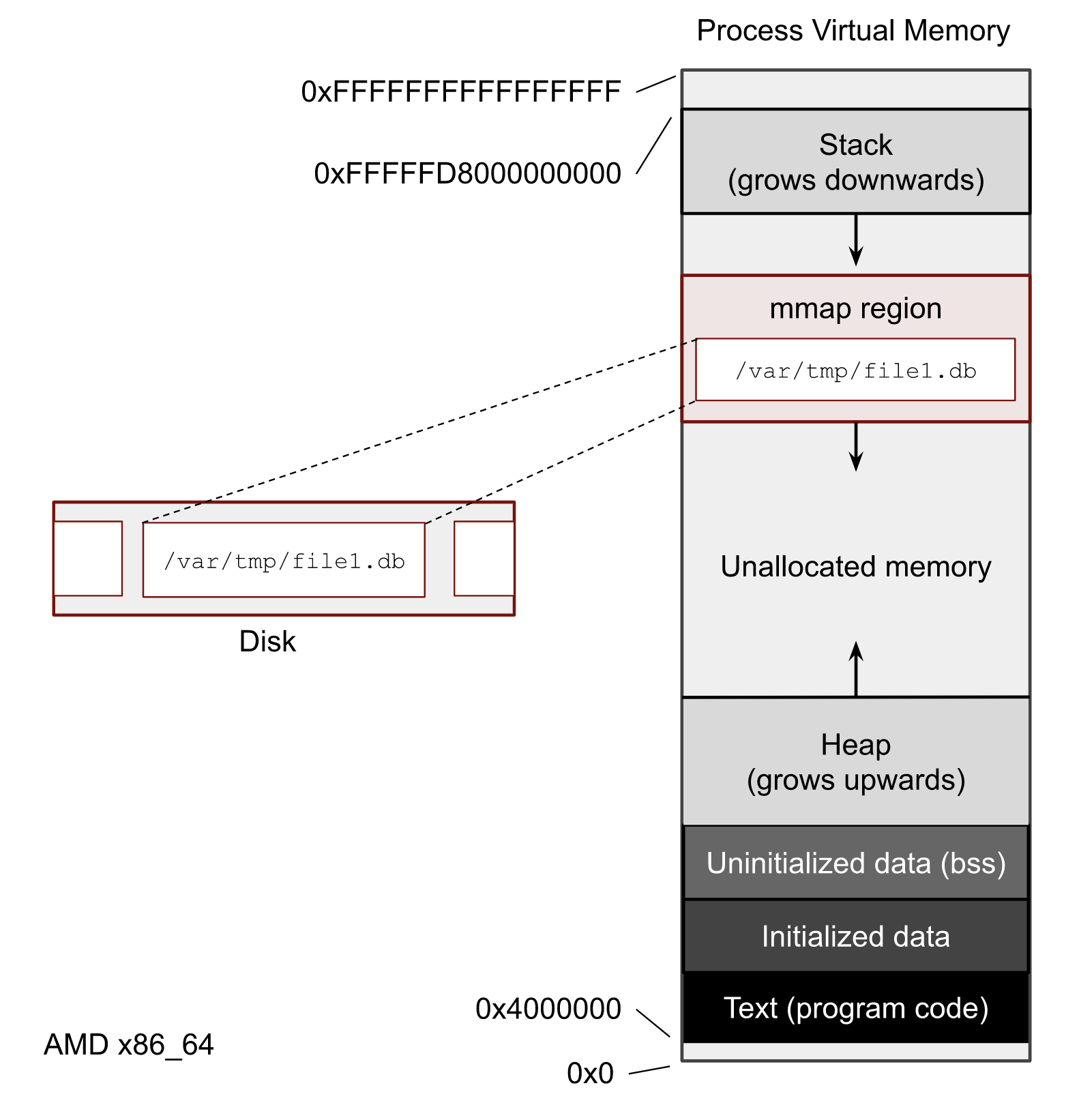
我们可以通过 pmap 来查看地址的映射关系。使用 pmap -X 或者 pmap -XX 可以显示更多信息
$ pmap -x 520290
520290: python t.py
Address Kbytes RSS Dirty Mode Mapping
000057228a4a5000 4 4 0 r---- python3.13
000057228a4a6000 4 4 0 r-x-- python3.13
000057228a4a7000 4 0 0 r---- python3.13
000057228a4a8000 4 4 4 r---- python3.13
000057228a4a9000 4 4 4 rw--- python3.13
00005722b429d000 944 844 844 rw--- [ anon ]
000073d925c00000 131072 0 0 r--s- file1.db
000073d92dcbf000 1284 644 644 rw--- [ anon ]
000073d92de00000 6092 4096 0 r---- locale-archive
000073d92e416000 1024 928 928 rw--- [ anon ]
000073d92e516000 60 60 0 r---- libm.so.6
---------------- ------- ------- -------
total kB 149756 13060 3236
我们可以看到文件有 0 个肮脏页面。 RSS 列等于0,它告诉我们过程中已经引用了多少内存。顺便说一句,这个0并不意味着页面缓存中没有文件页面。这意味着我们的流程尚未访问任何页面。
Page Fault#
页面错误(Page Fault) 是 Linux 内核管理虚拟内存的核心机制。
mmap() 不会立即分配物理内存,而是通过页表记录内存映射信息,直到进程真正访问该内存区域时才触发分配。
次级页面错误(Minor Page Fault):不涉及磁盘访问,仅更新进程页表。
主要页面错误(Major Page Fault):需要从磁盘读取数据到 Page Cache。
示例:
- 如果
mmap()访问的文件部分已经在 Page Cache 中 → 触发次级页面错误(不需要访问磁盘)。 - 如果访问的文件部分不在 Page Cache 中 → 触发主要页面错误(需要从磁盘加载数据)。
按需分页(Demand Paging) 允许 Linux 延迟实际内存分配,优化性能和资源使用。
系统 page fault 统计
$ sar -B 1
08:57:39 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s pgprom/s pgdem/s
08:57:40 PM 0.00 16.00 14522.00 0.00 9372.00 0.00 0.00 0.00 0.00 0.00
$ sudo perf trace -F maj --no-syscalls
0.000 ( 0.000 ms): tee/569900 majfault [elf_load+0x20f] => 0x59e5e5c74098 (?k)
35.338 ( 0.000 ms): grep/569918 majfault [0x14984] => /etc/ld.so.cache@0x0 (d.)
239.249 ( 0.000 ms): zsh/569897 majfault [0x748ee69268b0] => 0x748ee69268b0 (?.)
239.876 ( 0.000 ms): zsh/569897 majfault [0x748ee6909f80] => 0x748ee6909f80 (?.)
240.551 ( 0.000 ms): zsh/569897 majfault [0x748ee68d9204] => 0x748ee68d9204 (?.)
241.404 ( 0.000 ms): zsh/569897 majfault [0x748ee6849e60] => 0x748ee6849e60 (?.)
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.stat | grep fault
workingset_refault_anon 0
workingset_refault_file 0
pgfault 26545581
pgmajfault 291
thp_fault_alloc 25
numa_hint_faults 0
- 默认情况下,Linux 不会主动回收 Page Cache,除非系统存在内存压力。
madvise(ptr, size, MADV_DONTNEED)显式通知内核移除这些页面。vmtouch -e可以驱逐大部分页面,但如果MADV_DONTNEED未使用,一些页面仍可能保留。- 在内存不足时,内核才会主动回收 LRU 页面,从而最终释放
mmap()映射的文件数据。
Cgroups V2#
systemd-cgls 与 systemd-cgtop
systemd-cgls:以树形层级展示当前 cgroup(统一层级 v2)结构与进程归属,用于定位进程所在 cgroup 路径。systemd-cgtop:按 cgroup 聚合展示 CPU/内存/IO 等资源消耗的采样视图,便于观察某个 cgroup 的瞬时开销。
几个 cgroup 相关的文件#
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.stat | grep file
file 352112640
file_mapped 67641344
file_dirty 98304
file_writeback 0
file_thp 14680064
inactive_file 312410112
active_file 68870144
workingset_refault_file 2661
workingset_activate_file 92
workingset_restore_file 0
file– 页面缓存的大小file_mapped– 映射文件内存大小,其中mmap()file_dirty– 脏页大小file_writeback– 当前正在刷新的数据量inactive_file和active_file– LRU 列表的大小workingset_refault_file、workingset_activate_file和workingset_restore_file– 用于更好地理解内存抖动和重故障逻辑的指标
memory.min 、 memory.low 、 memory.high 和 memory.max ——cgroup 限制
memory.events ——显示 cgroup 达到上述限制的次数:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.events
low 0
high 0
max 0
oom 0
oom_kill 0
oom_group_kill 0
PSI#
https://www.kernel.org/doc/html/latest/accounting/psi.html
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-2.scope/memory.pressure
some avg10=0.00 avg60=0.00 avg300=0.00 total=254596
full avg10=0.00 avg60=0.00 avg300=0.00 total=254264
其中
some– 表示在 10 秒、60 秒和 300 秒内,至少有一个任务因内存问题而停滞了一段时间(占总时间的平均百分比)。total字段显示了以微秒为单位的绝对值,以揭示任何峰值;full– 表示 cgroup 中所有任务的相同情况。此指标是问题的一个良好指示,通常意味着资源供应不足或软件设置错误。
所有权#
来自不同 cgroup 的多个进程可以同时访问同一个文件。例如:cgroup1 打开并读取文件的前 10 KiB;稍后,cgroup2 在文件末尾追加 2 KiB,并再次读取文件的前 4 KiB。这种情况下,内核必须决定究竟应将内存与 I/O 的计费和限制归属到哪个 cgroup。
内存及其对应的 Page Cache 所有权以页(page)为粒度建立。当某个页首次被访问并触发缺页(page fault)时,该页会被“计费(charge)”到当时访问者所在的 cgroup,并在被完全回收并从 Page Cache 驱逐之前保持这一归属。也就是说,只要该页仍存在于缓存中,它始终被视为属于最早访问它的 cgroup;此归属关系会体现在该 cgroup 的统计数据中,例如 memory.stat 的 file、inactive_file 或 active_file 字段。
继续前面的例子:cgroup1 首次读取前 10 KiB,因此这部分页被计入它的 Page Cache 使用量;cgroup2 追加写入末尾的 2 KiB,则相应的页归属于它。当 cgroup2 之后再次读取文件开头的 4 KiB 时,只要这些页尚未被回收,它们仍归属于 cgroup1——即使 cgroup1 已经关闭文件或进程退出。只要这些页依旧驻留在 Page Cache 中,它们的内存消耗仍计入 cgroup1,内核会根据访问与老化状态,将这些页维持在对应的 LRU 列表中。这种行为导致所谓的“历史持有”现象:即便当前的主要访问者已发生变化,缓存页依旧挂在先前的 cgroup 名下。
页的所有权只有在其被完全回收并重新由新的 cgroup 访问时才会发生迁移。因此,当多个 cgroup 共享同一份热数据时,memory.current 或 memory.stat 中显示的缓存占用反映的是“拥有者”,而非“当前使用者”,这容易造成谁在“占用缓存”的误判。
与内存不同,I/O 的所有权是以 inode 为粒度管理的。
当文件产生脏页并触发写回(writeback)时,该写回最初会计入触发写回的 cgroup。
例如,如果 cgroup2 首次生成该文件的脏页并导致写回启动,那么这次写回 I/O 的计费就会归属于 cgroup2。
然而,与页所有权不同,写回归属并非固定不变:当内核检测到另一个 cgroup 成为该文件的主要写入者时,写回归属可能会迁移至新的 cgroup,以避免写入压力分配的不公平